CS 5614 Homework #1
Date Assigned: August 27, 1999
Date Due: September 3, 1999, in class, before class starts
- (10 points) The network database model was one of the first models
of database systems. The idea is to view data as a graph of
records (In fact, later models can be viewed as restrictions
of this basic idea; the hierarchical model organizes data as
a forest, instead of an arbitrary graph). Each tuple from a table in
a conventional RDBMS is stored
as a separate record and has identity distinct from the other records
(tuples). The connection between records is effected by
extensive use of links (pointers).
For example, here is a rudimentary network database:
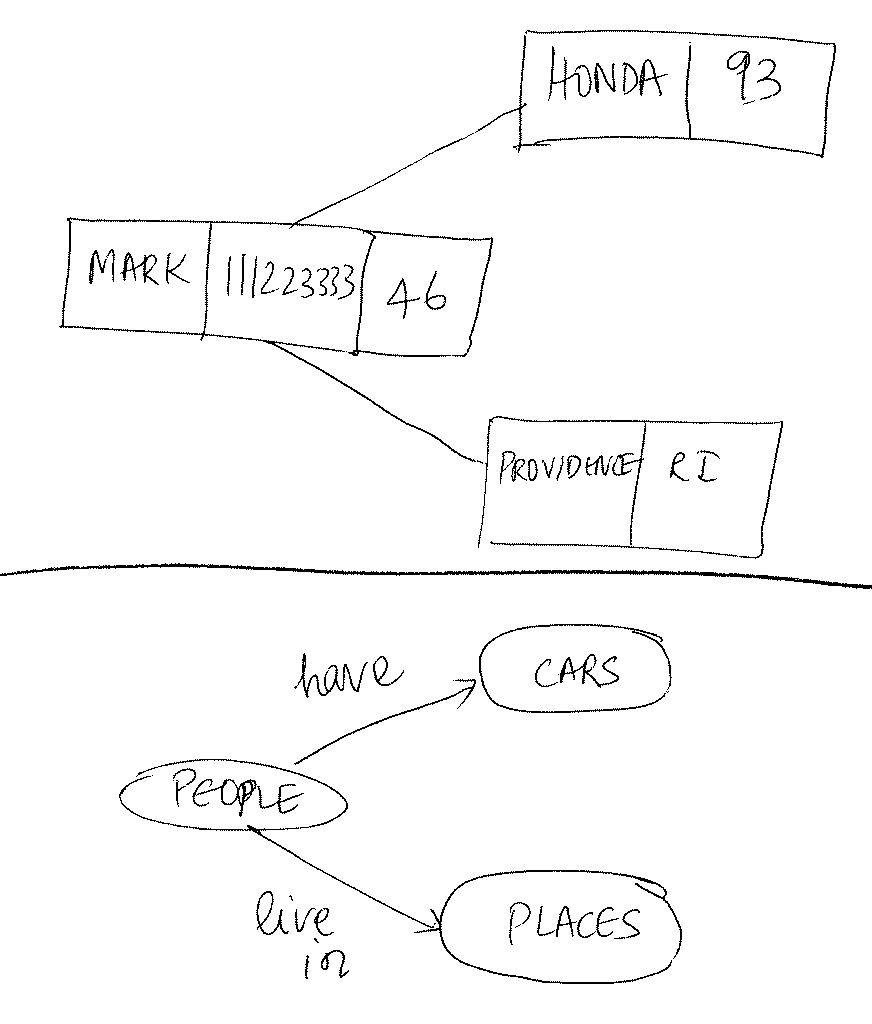 The top portion of the picture depicts three actual records being
linked to each other. The bottom portion indicates the schema (for
example, it reveals that people-to-cars is many-to-one and
people-to-places is also many-to-one). In other words, many
people can have one car and many people can be in one place.
One peculiarity of this model was that all links are restricted
to be many-one connections. Thus, if there is a link between
two records A and B, and it is many-one from A to B, then
A is called the "member" record and B is called the "owner"
record. Each owner record therefore can be linked to many
member records but one member record can be linked to only one
owner record. (If you wanted to model a many-many relationship,
you would have to introduce a "in-between" record and replace
it with two many-ones).
The top portion of the picture depicts three actual records being
linked to each other. The bottom portion indicates the schema (for
example, it reveals that people-to-cars is many-to-one and
people-to-places is also many-to-one). In other words, many
people can have one car and many people can be in one place.
One peculiarity of this model was that all links are restricted
to be many-one connections. Thus, if there is a link between
two records A and B, and it is many-one from A to B, then
A is called the "member" record and B is called the "owner"
record. Each owner record therefore can be linked to many
member records but one member record can be linked to only one
owner record. (If you wanted to model a many-many relationship,
you would have to introduce a "in-between" record and replace
it with two many-ones).
Your task is to figure out why the original designers made this
ad-hoc restriction to many-one relationships (it is there for a reason,
all right). What implementation advantage(s) does it provide over the
more general many-many modeling?
- (5+5+5=15 points) In addition to indices, commercial DBMSs provide
"table scan" operations - these are operations
that are meant to read many blocks (pages)
in one stroke, provided the table is stored in contiguous locations.
In fact, one of the tricks employed by DBMS vendors is to store data pertaining
to one single relation on the same cylinder. Thus, if you are attempting
to read all data from a single relation, then you just have to position
the arm once for all reads from all the platters (the first
and one of the expensive parts of the access time - the seek time -
thus needs to be accounted for only once, in the beginning).
For example, Ingres can read nearly 10 pages in a "scan" and this
is sometimes beneficial (upto 10 times faster) to using a secondary index,
even (and particularly) if the index returns all the pages of the table.
Assume that a table has 2 million records and a query returns 75,000 records.
Assume, further, that a block contains 22 records. Is it beneficial to
have a secondary index? Why/Why not? What if there are only 2 records
per block?
What guidelines can you provide for when to use secondary indices?
- (60 points) This problem is taken from the Heiro-book. Assume that
blocks can hold either 10 records or 99 keys and 100 pointers. Also assume
that the average B-tree node is 70% full i.e., it will have 69 keys
and 70 pointers. We can use B-trees as part of several different structures.
For each structure defined below, determine (a) the total number
of blocks needed for a 1,000,000-record file, and (b) the average
number of disk accesses to retrieve a record given its search key.
You may assume that nothing is in main memory already, and that the
search key is the primary key for all the records.
- The data file is a sequential file, sorted on the search key,
with 10 records per block. The B-tree is a dense index.
- The same as (1) but the data file is not sorted and the records
are still 10 to a block.
- The same as (1) except that the B-tree is now a sparse index.
- Instead of the B-tree leaves having pointers to records, the B-tree
leaves hold the records themselves. A block can hold ten records (as
stated previously), but on average, a leaf block is 70% full. i.e.,
there are 7 records per leaf block.
- (5 points) A diligent student pointed out in Wednesday's class
that a third way to organize indices is as a multi-level mechanism,
i.e., indices point to indices that point to the data sources.
Since we have a choice of sparse/dense indices, comment on
what are good choices of indices to have at each level.
- (10 points) We mentioned in class that the choice of an index,
to a certain extent, depends on (and influences) the physical organization of
data on secondary storage. Give an example of a physical organization
of data (i.e., something like sorted files/B-trees/hash tables)
where a secondary index is needed even on the primary key!
Explain why.
