Everything is a Matrix (IR and NA viewpoints)
- term-document matrix in IR

- people-artifacts matrix in RS

- hyperlink matrix in web modeling
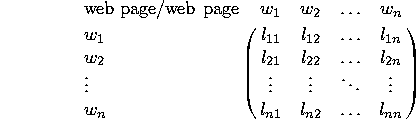
Some points to note about the above formulations
- Choice of terms, documents etc. is very domain-specific. For example, stemming and stopwords are commonly accepted as pre-processing steps in IR to obtain a "good" term-list.
- The first two matrices are typically very lopsided. For example,
in IR,
 or
or 
- What do we put inside the matrices: (i) a zero if not applicable (term doesn't appear in document, person doesn't rate artifact etc.), (ii) the non-zero entries can denote various properties of the "presence", such as frequency, inverse frequency etc. There is ages of literature pertaining to what is the "right" way to capture the non-zero entries.
- The web matrix is square and typically not symmetric.
- All three types of matrices are usually 99.9% sparse!
What can we do with these matrices?
- Answer a query
- Study the space (spanned by the vectors of the matrix)
- Study the effect of the matrix in this space
- Do interesting data mining by tinkering with the matrices
Answer a Query
 The dot-product of two vectors is denoted by:
The dot-product of two vectors is denoted by:
![]()
![]()
Thus, the angle between two vectors is given by:
![]()
(Document) vectors whose cosine metric is within a threshold (typically
> 0.5) are "retrieved." For the above query, documents d1 and d2
would be
deemed similar (with d2 being twice as similar).
Some points about this model:
(i) Notice that while the dot-product calculation looks cumbersome,
the
number of entries that have non-zeros in both elements of the product would
be very few (these are the ones that would contribute to a non-zero
dot product). Still, this can get compute-intensive for higher dimensions.
(ii) One simplification that people resort to is to normalize
all document vectors (to have length one).
(iii) Retrieval is not "exact" (which is desirable). For example, the
document does not need to have all the terms in the query to "qualify." However,
the vector-space model does not model term-term correlations, so it will
not bring documents that are connected in two-steps together. Thus,
d3 will not be returned
for the query, even though "data structures" have something to do with "theory".
Simple fixes to this problem are the term-weighting approaches, and use of
a thesaurus (sometimes called a lexicon), that explicitly models such
correlations. Still the fundamental problem remains
that in the vector-space model, terms are assumed to be independent and orthogonally
spanning a space. Finally,
(iv) there is a need to compare the query vector with every possible
document vector to ensure that no relevant document is left behind (i.e.,
there is no pre-processing, akin to a lazy approach).
Study the space




The rank of an IR matrix is typically much much smaller than either of the two dimensions (terms or documents), since there will be some redundancy among the vectors in the matrix.
Analyze the effect of the matrix in the space
- The eigen values of a diagonal matrix are just the diagonal elements.
- The eigen values of an upper triangular (or lower triangular) matrix are (also!) sitting along the diagonal (why?)
- The sum of the eigen values is equal to the sum of the diagonal elements (yes, this holds for any matrix!) and is called the trace of the matrix.
- The product of the eigen values is equal to the determinant of the matrix.
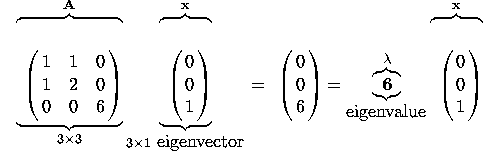
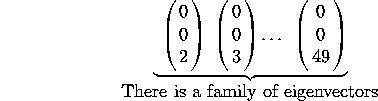
![]()
A cute result involving eigen vectors is the following: If you construct a matrix S of the eigen vectors as follows:
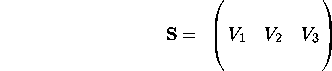
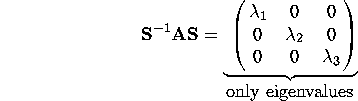
Or, we can think of this as:
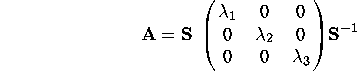
The matrix A is said to be diagonalized. Diagonalization can be thought of as a neat mathematical way to bring about the structure of a matrix. S is sometimes called the eigen-vector matrix and the diagonal matrix of eigen values is sometimes called the eigen-value matrix. Diagonalization is also a way of showing the rank of the matrix explicitly (the number of non-zero diagonal elements in the middle matrix). We are thus introduced to our first decomposition.
Mining Using Matrix Decompositions: A Packaging Analogy
Why these things should work as well as they do, nobody knows.
What we will cover in detail
- SVD: The mother of all decompositions, decompose according to principal components.
- SDD: Overcomes sparsity destroyed by SVD.
- The paper by Booker et al: Decompose-as-you-like-it.
- The paper by Jiang and Littman: a novel way of parameterizing (three) decompositions.
- NMF: An interesting constraint imposed to obtain "additive" factors.
- The CLEVER project: close cousin of the QR decomposition.
