Discussion Notes
Mar 19, 2001
(courtesy Iype Isac)
Today's readings discuss techniques for extracting the structure of web pages. Together with last class's readings, a taxonomy can be visualized as:
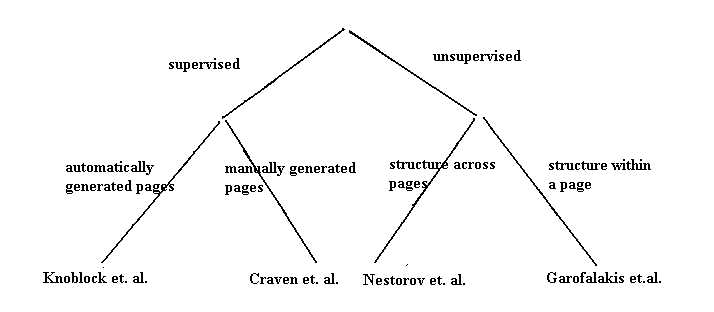
In the case of unsupervised learning, recall that there is no such thing as a correct schema; which is why the authors bring in metrics to measure and choose between schemas. This is where they diverge from last class, where there was an agreed upon notion of correctness.
Extracting Schema from semistructured data
The Nestorov paper models a graph based structure, to represent structure across webpages.
- groups webpages into similar types (try to find the minimal perfect typing for the webpages)
- monadic (single argument) datlog programs can be used to type data.
- excess and deficit facts due to typing
- multiple roles can be assumed in the grouping (one node can serve more than a single purpose)
Consider the example give below
o1 -------> o2 a
There are two objects here, o1 and o2. Now there are many ways of grouping (either o1,o2 in the same class or in different classes). We try to find a typing for the above relation and group o1 and o2 into classes. Consider the typing (P) below
T2(X):- T1(Y),link(Y,X,"a"). T1(X):- T2(Y),link(X,Y,"a").
By T1(o1) we mean map object o1 to type T1, and so on. In computing the MPT for the program, we plug in all the different values for X in the two rules. If the mapping of two objects to the same type is true, then the two objects will be grouped together. For the first iteration, try all the mappings with the typing.
T1(o1):- this turns out to be false. T2(o1):- this turns out to be true. T1(o2):- this turns out to be true. T2(o2):- this turns out to be false.
A further iteration doesn't lead to any changes. So a possible mapping of objects to the types is o1 belongs to type T2 and o2 belongs to type T1. This is a perfect typing. The only problem with the above mapping is that it is too exact a representation. For real-world applications, it may be too large. So rather than a perfect schema, approximate typings are considered.
XTRACT
- extracts the regular expression for the DTD (Document Type Descriptors) of webpages.
- MDL minimum description length principle used (for a "concise" and "precise" regular expression)
- 3 steps in getting the regular expression: generalisation (to make the regular expression general), factorization (to make the regular expression shorter), and choosing a suitable regular expression using the MDL principle.
- a grammar-like procedure for determining the MDL cost is given.
